There is a discipline that has been quietly emerging across software, machine learning, and AI systems engineering for the past decade, and it has not yet had a name. Test harnesses gave us its pattern: a controlled environment that drives an artifact and watches it react. Compound AI systems gave us its scope: the unit under test is no longer a function or a model, it is a system of model calls, retrievers, and tools. The literature on hidden technical debt in machine learning gave us its urgency: at the system level, debt compounds silently, and only system-level instrumentation pays it down. This post pulls those threads together and names the discipline that ties them: harness engineering.
Test Harness
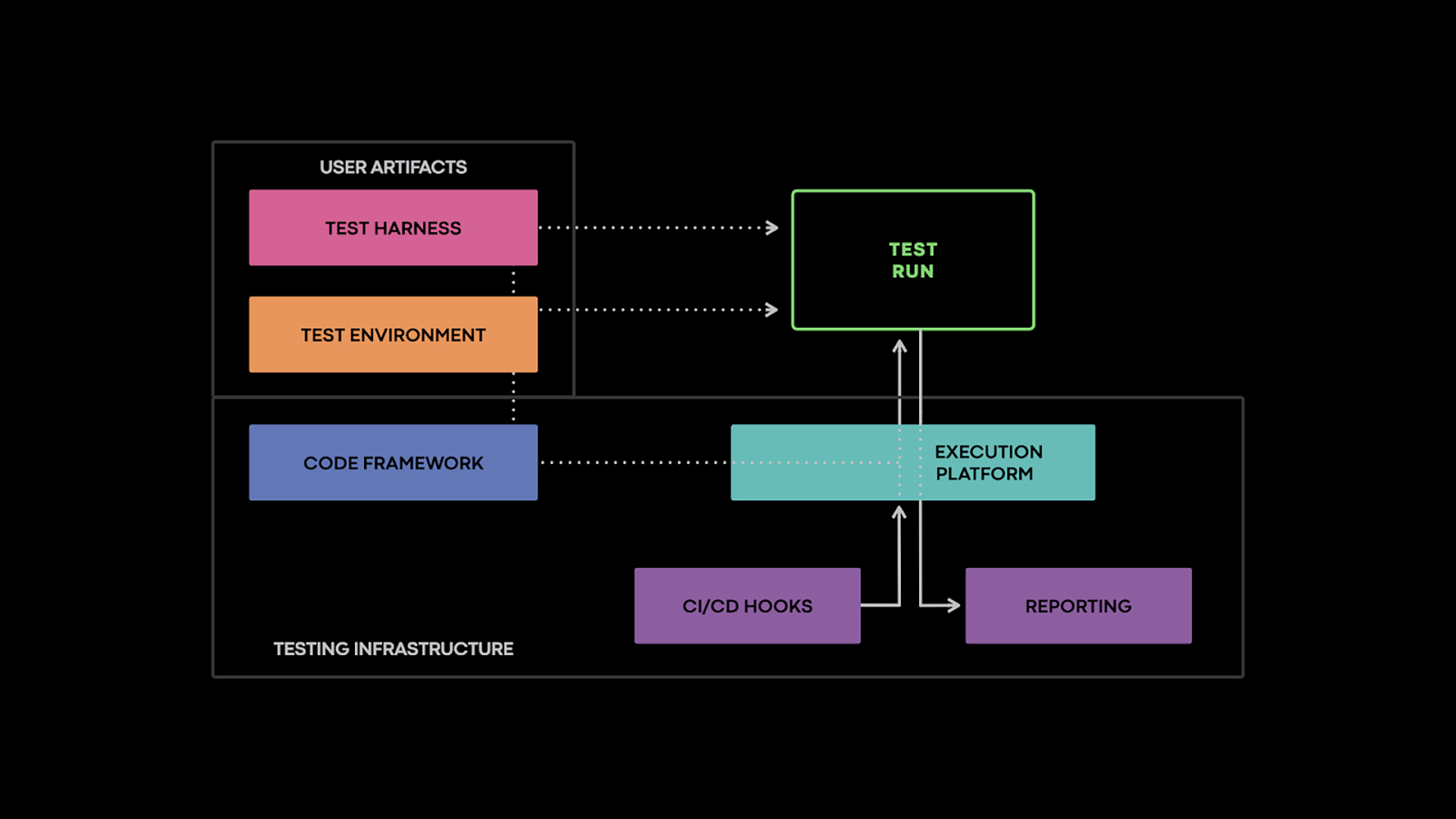
A test harness in software testing is a structured collection of tools, test data, stubs, drivers, and automation scripts used to execute tests when key modules are incomplete, unavailable, or still under development. It creates a controlled test environment that mimics real system behavior without depending on external systems.
The pattern is older than any of its modern incarnations. A harness sits next to the artifact under test, drives it through a defined interface, substitutes its dependencies with stubs or mocks, and inspects the resulting behavior against an oracle. Meta's integration testing infrastructure expresses this pattern at scale: a test harness, in their words, is “a program that gets executed in the test environment alongside the service(s) under test,” exercising it through RPCs or by mutating the environment around it. Mocks intercept calls to dependencies, an isolation layer prevents tests from leaking into production, and oracles assert against the externally visible behavior of the service.
The same infrastructure scales further into autonomous testing — fuzzing services with generated or recorded inputs, automatically detecting crashes, undeclared exceptions, and SQL or code-injection signals. What changes is the inputs and the oracles; what stays constant is the harness pattern: an artifact under test, scaffolding around it that drives execution, mocks dependencies, and observes outcomes. That triplet — drive, isolate, observe — is the seed of everything that follows in this post.
Source: Autonomous Testing of Services at Scale — Paul Marinescu, Meta Engineering, October 2021.
Compound AI System
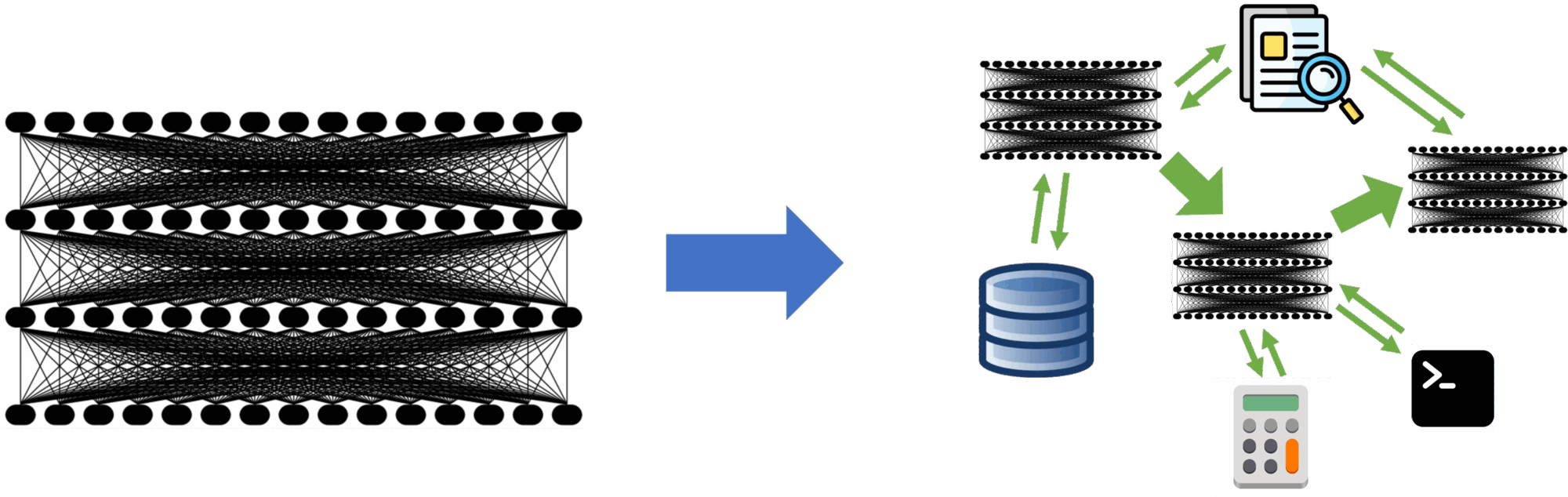
Zaharia and colleagues at Berkeley AI Research define a compound AI system as a system that tackles AI tasks using multiple interacting components — multiple calls to models, retrievers, or external tools — in contrast to an AI model, which is a single statistical artifact. AlphaCode 2 generates a million candidate solutions and filters them. AlphaGeometry pairs an LLM with a symbolic solver. Sixty percent of LLM applications inside Databricks use retrieval-augmented generation; thirty percent use multi-step chains. The authors argue, with substantial evidence, that “state-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models.”
The reasons they offer for this shift are practical: many tasks are easier to improve by system design than by scaling training; systems can be dynamic where models are static; control and trust are easier to engineer at the system level than to train into a model; and applications need to vary cost and quality in ways no single model offers. Each of those reasons relocates the engineering frontier from inside the model to around it.
What this leaves us with is a new and harder unit of analysis. The compound AI paper identifies three challenge axes that follow directly from this relocation: design space (the combinatorial problem of choosing components, retrieval strategies, and resource budgets), optimization (co-tuning components that are not jointly differentiable), and operation (monitoring, debugging, and securing systems whose per-input behavior is no longer a single forward pass). Read those three axes carefully: they are exactly the axes a harness must address. The compound system is the new unit under test.
Source: The Shift from Models to Compound AI Systems — Zaharia et al., BAIR Blog, February 2024.
ML Technical Debt
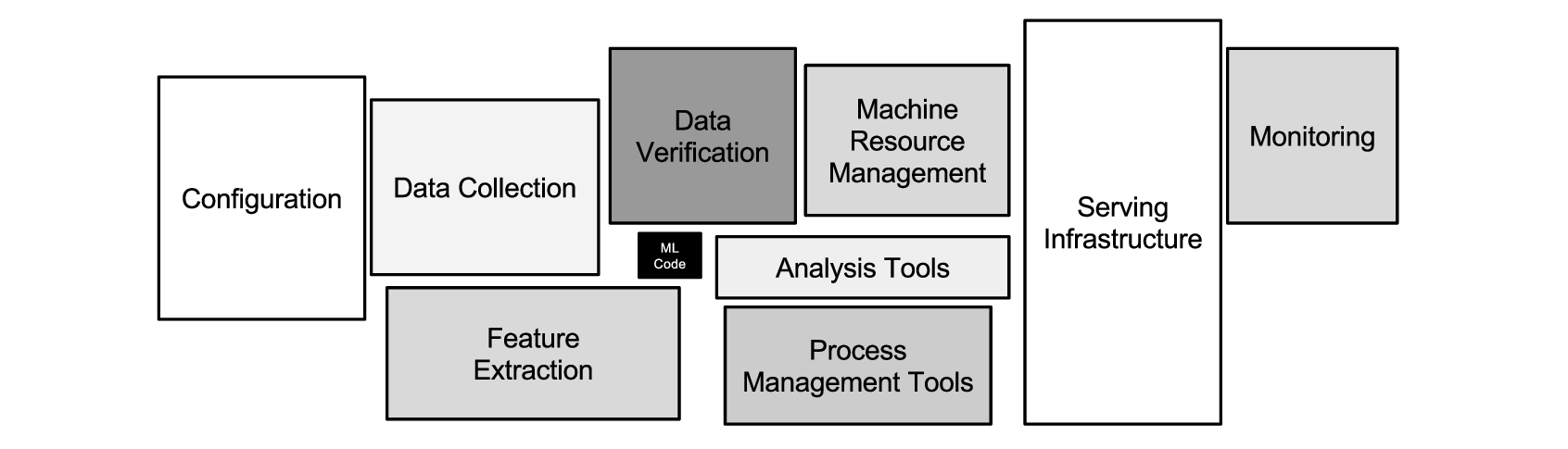
If compound AI systems show us the new unit under test, Sculley and colleagues at Google showed us, a decade earlier, why we cannot afford to leave it untested. Their NeurIPS 2015 paper Hidden Technical Debt in Machine Learning Systems reframes the maintenance cost of ML not as code-level debt but as system-level debt — debt that is invisible to ordinary refactoring and that compounds silently because it spans data, configuration, and the boundary between the model and the world.
Their catalogue is by now famous. Entanglement: in a learned model, no input is ever really independent — the “CACE principle”, Changing Anything Changes Everything. Hidden feedback loops: live systems influence their own future training data, and two disjoint systems can entangle through the world. Undeclared consumers: a model's output, once exposed, accretes silent downstream dependencies that turn every change into a coupling problem. Glue code and pipeline jungles: the famous figure above — the small black box of ML code surrounded by configuration, data collection, feature extraction, serving, and monitoring — reflects the empirical reality that a mature ML system is often 5% machine learning and 95% scaffolding. Configuration debt: in a mature system, lines of configuration outnumber lines of code, and each line is a potential mistake.
The mitigations Sculley and colleagues propose are not algorithmic. They are infrastructural: static analysis of data dependencies, leave-one-feature-out evaluations to flush out underutilized inputs, prediction-bias monitoring, action limits, propagating SLOs upstream and downstream, automated quality evaluation, versioned signals. Read those mitigations as a list, and a shape emerges. They are all instances of the same operation: take an artifact in a running system, surround it with controlled drivers and observers, close the loop with feedback. Sculley et al. did not call this harness engineering — the name was not yet in the air — but they catalogued precisely the problems that demand it.
Source: Hidden Technical Debt in Machine Learning Systems — Sculley et al., NeurIPS 2015.
Harness Engineering
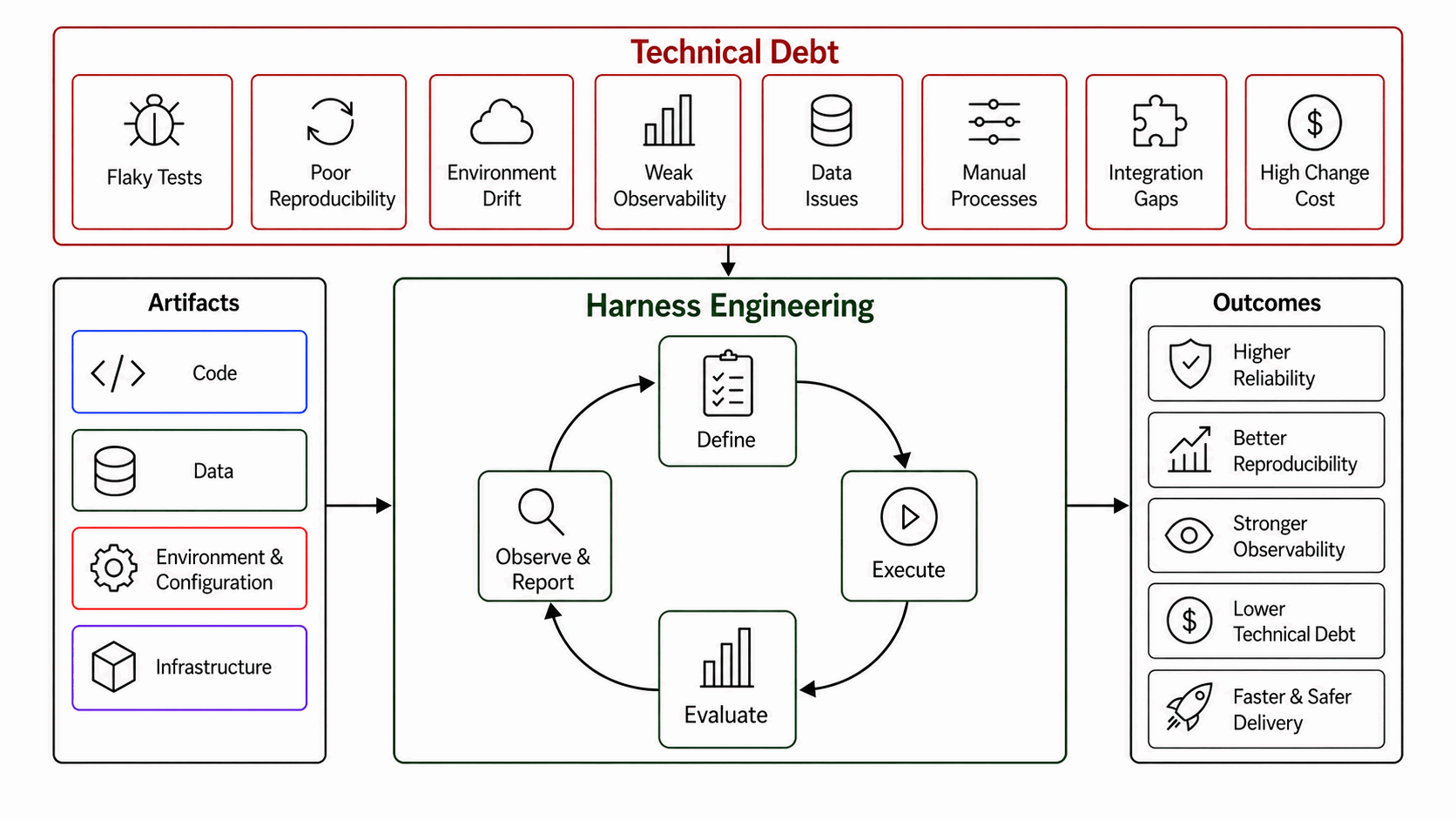
What is harness engineering?
Harness Engineering is an engineering discipline for systematically connecting system artifacts with controlled execution, evaluation, and observation through a continuous feedback loop to reduce technical debt and improve system quality.
The three preceding sections are the answer to three questions about this definition. Where does the discipline come from? From the test harness pattern: an artifact under test, surrounded by scaffolding that drives it, mocks its dependencies, and watches it react. What is its scope today? The compound AI system — a graph of model calls, retrievers, tools, and conventional code — whose design space, optimization, and operation no longer fit inside a single forward pass. Why is it needed now? Because hidden technical debt at the system level is silent, compounding, and unpayable by code-level instruments alone.
The diagram above is a literal map of the discipline. Read it as four pieces.
Artifacts (the inputs)
On the left of the diagram are the four kinds of artifact a harness connects to:
- Code
- Application source, services, libraries, agents — the conventional software half of any modern system.
- Data
- Training data, evaluation sets, retrieval corpora, feature stores, and the live data the system serves and consumes.
- Environment & Configuration
- Runtime settings, feature flags, model parameters, prompts, routing rules — the lines of configuration that, in a mature system, outnumber lines of code.
- Infrastructure
- The compute, storage, networking, and orchestration the system runs on. Containerisation, isolation, and routing are first-class harness concerns, as the Meta autonomous-testing infrastructure shows.
Together, these are the unit under test in the modern world: not a function, not a model, but a compound AI system or service whose surface area spans all four artifact types.
The harness loop (the four steps)
At the centre of the diagram is the loop. It runs continuously, not once per CI build:
- Define
- Specify what is to be harnessed: the artifact under test, the interfaces, the inputs, and what counts as success. Thrift IDLs, prompt and signature definitions (DSPy), evaluation rubrics, SLOs, and action limits all live here. The test-harness pattern takes this step for granted; in modern systems it has to be made explicit.
- Execute
- Drive the artifact through its defined interface in an isolated environment — with mocks, recorded inputs, and fuzzed variants when appropriate. This is the inheritance from the test-harness pattern. The Meta blog gives the canonical machinery for executing services under controlled conditions.
- Evaluate
- Apply oracles for a world where the right answer is not always a single value. Co-optimisation of non-differentiable pipelines (DSPy), routing under quality-cost trade-offs (FrugalGPT and AI gateways), LLM-as-judge, and rubric-based grading all sit here. Evaluation is what turns a run into a signal.
- Observe & Report
- Surface what happened: prediction-bias tracking, action limits, propagated SLOs, monitored data dependencies, traces through complex AI systems. Observation turns a signal into knowledge; reporting feeds it back into the next Define step.
Technical debt (the forces countered)
Across the top of the diagram are the eight forces a harness exists to counter — the system-level debts Sculley and colleagues catalogued and that compound silently in any unharnessed system: flaky tests, poor reproducibility, environment drift, weak observability, data issues, manual processes, integration gaps, and high change cost. Each is invisible to code-level instrumentation and unpayable by ordinary refactoring.
Outcomes (the outputs)
On the right of the diagram are the outcomes a healthy harness produces, and the metrics by which it justifies its own cost: higher reliability, better reproducibility, stronger observability, lower technical debt, and faster and safer delivery. The outcomes are not aspirational claims; they are the direct consequences of running the loop continuously over the artifacts and against the eight forces of debt.
The continuous feedback loop
The arrow from Observe & Report back to Define is the part that makes this an engineering discipline rather than a one-off setup. A test harness that runs in CI gives you a verdict per commit. A harness for a live compound system has to run continuously, against shifting data and a moving external world, and feed observation back into definition — into prompt and weight updates, retrieval indexes, configuration, routing policies, evaluation rubrics, and the catalogue of what counts as healthy behavior. The loop is what keeps technical debt observable, and observable debt is the only kind that gets paid down.
Naming this discipline is not a rebranding exercise. It is the recognition that the work spread across testing infrastructure teams, ML platform teams, MLOps and LLMOps teams, and the new generation of AI evaluation tooling is one body of work with one shape. Harness engineering is what it has been all along.
References
- Marinescu, P. (2021). Autonomous Testing of Services at Scale. Meta Engineering Blog, October 20, 2021. https://engineering.fb.com/2021/10/20/developer-tools/autonomous-testing/
- Zaharia, M., Khattab, O., Chen, L., Davis, J. Q., Miller, H., Potts, C., Zou, J., Carbin, M., Frankle, J., Rao, N., & Ghodsi, A. (2024). The Shift from Models to Compound AI Systems. BAIR Blog, February 18, 2024. https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
- Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems (NeurIPS) 28. https://papers.nips.cc/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html